科技赋能 运用先进数据处理技术,正确分析数据以提升公司效率

在当今数据驱动的商业环境中,数据已成为企业的核心资产。正确分析数据并利用先进的数据处理技术,是提升公司运营效率、优化决策、驱动创新的关键。本文旨在探讨如何构建科学的数据分析流程,并阐述相关数据处理技术开发的重要性与实践路径。
一、 建立正确的数据分析思维与流程
正确的数据分析始于明确的目标和科学的流程,而非简单的工具堆砌。
- 目标导向与问题定义:分析的首要步骤是明确业务目标。是希望提升生产效率、降低运营成本、优化客户体验,还是发现新的市场机会?清晰的问题定义是确保分析工作不偏离轨道的基石。
- 数据收集与整合:确保数据来源的可靠性、一致性和完整性。这需要打破部门数据孤岛,整合来自生产、销售、财务、客户服务等多渠道的结构化与非结构化数据,形成统一的数据视图。
- 数据清洗与预处理:原始数据往往包含噪声、缺失值和异常值。通过数据清洗、转换和归一化等预处理步骤,为后续分析提供高质量的数据基础,这是保证分析结果准确性的关键环节。
- 探索性分析与建模:运用统计分析、可视化工具探索数据内在规律。基于业务问题,选择合适的分析模型(如描述性分析、预测性分析或规范性分析)进行深入挖掘。
- 解读结果与行动洞察:分析的价值在于产生可执行的洞察。分析师需将数据结果转化为通俗易懂的业务语言,明确“数据告诉我们什么”以及“我们应该做什么”,推动决策与行动。
- 持续监控与迭代优化:建立数据指标体系,持续监控关键绩效指标(KPIs)的变化,并根据业务反馈和新的数据,不断迭代优化分析模型与策略。
二、 关键技术开发:数据处理技术的核心支柱
高效、准确的数据分析离不开底层强大的数据处理技术支撑。相关技术开发正朝着实时化、智能化、平台化方向发展。
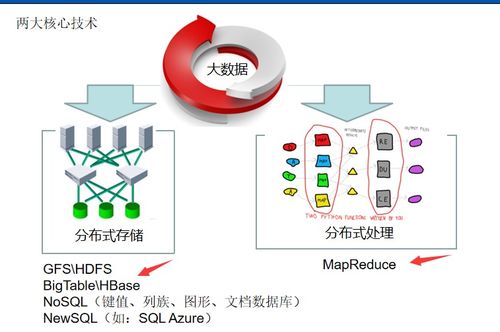
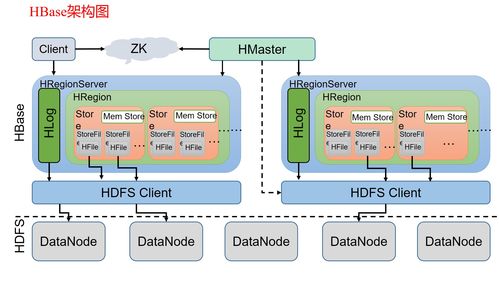
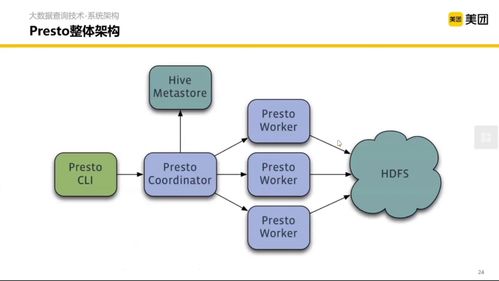
- 大数据处理框架:如Apache Hadoop、Spark等分布式计算框架,能够处理海量、高速、多样的数据,为大规模数据分析提供算力基础。开发重点在于优化资源调度、提升计算效率与降低成本。
- 实时流处理技术:对于需要即时响应的场景(如欺诈检测、实时推荐),Flink、Kafka Streams等技术实现了数据的实时摄入、处理与分析,极大缩短了从数据到决策的周期,直接提升运营响应效率。
- 云原生与数据湖仓:基于云平台(如AWS, Azure, GCP)的数据湖和数据仓库解决方案,提供了弹性、可扩展的存储与计算能力。技术开发聚焦于实现湖仓一体,兼顾数据湖的灵活性与数据仓库的管理规范性,简化数据架构。
- 人工智能与机器学习集成:将机器学习算法(如预测模型、聚类分析、自然语言处理)深度集成到数据处理流水线中,实现自动化洞察与智能决策。AutoML等技术正在降低模型开发与应用的门槛。
- 数据治理与安全技术:在分析效率的必须保障数据质量、安全与合规。相关技术包括数据血缘追踪、元数据管理、隐私计算(如联邦学习)、差分隐私等,确保数据在可控、可信的环境下被使用。
- 低代码/无代码与自助式分析平台:通过开发用户友好的可视化数据分析工具和平台(如Tableau, Power BI的深度定制化),赋能业务人员自主进行探索性分析,减少对专业数据团队的依赖,加速分析民主化进程。
三、 融合实践:以技术驱动效率提升
将正确的分析流程与先进的技术相结合,方能最大化数据价值。
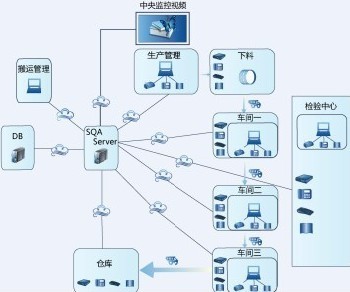
公司应构建一个从数据源到业务价值实现的闭环体系。例如,利用流处理技术实时监控生产线传感器数据,通过实时分析预测设备故障(预测性维护),并自动触发维修工单,从而减少停机时间,提升生产效率。通过整合客户交互数据,利用机器学习模型进行客户分群与需求预测,指导精准营销和产品开发,提升市场效率。
结论
确保公司效率的数据分析,是一个将科学方法论与前沿技术深度融合的系统工程。它不仅要求企业树立数据驱动的文化,建立严谨的分析流程,更要求持续投入数据处理技术的研发与应用,构建敏捷、智能、安全的数据基础设施。唯有如此,企业才能在数据的洪流中捕捉真知,将数据潜能转化为实实在在的运营效率与竞争优势。
如若转载,请注明出处:http://www.yingling8888.com/product/51.html
更新时间:2026-06-19 09:45:08